了解 JavaScript 的内存模型有助于了解 const 和 let,以及函数的参数传递。
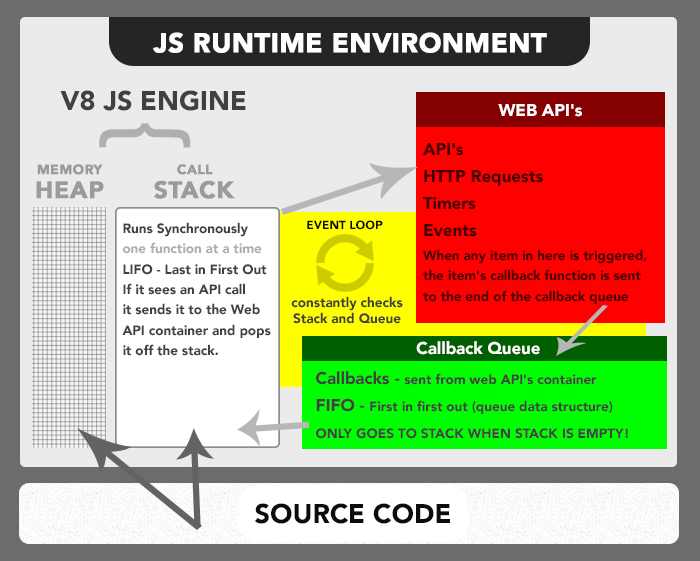
内存模型图:
(图片来自 网络)
简化版就是:
(图片来自 MDN)
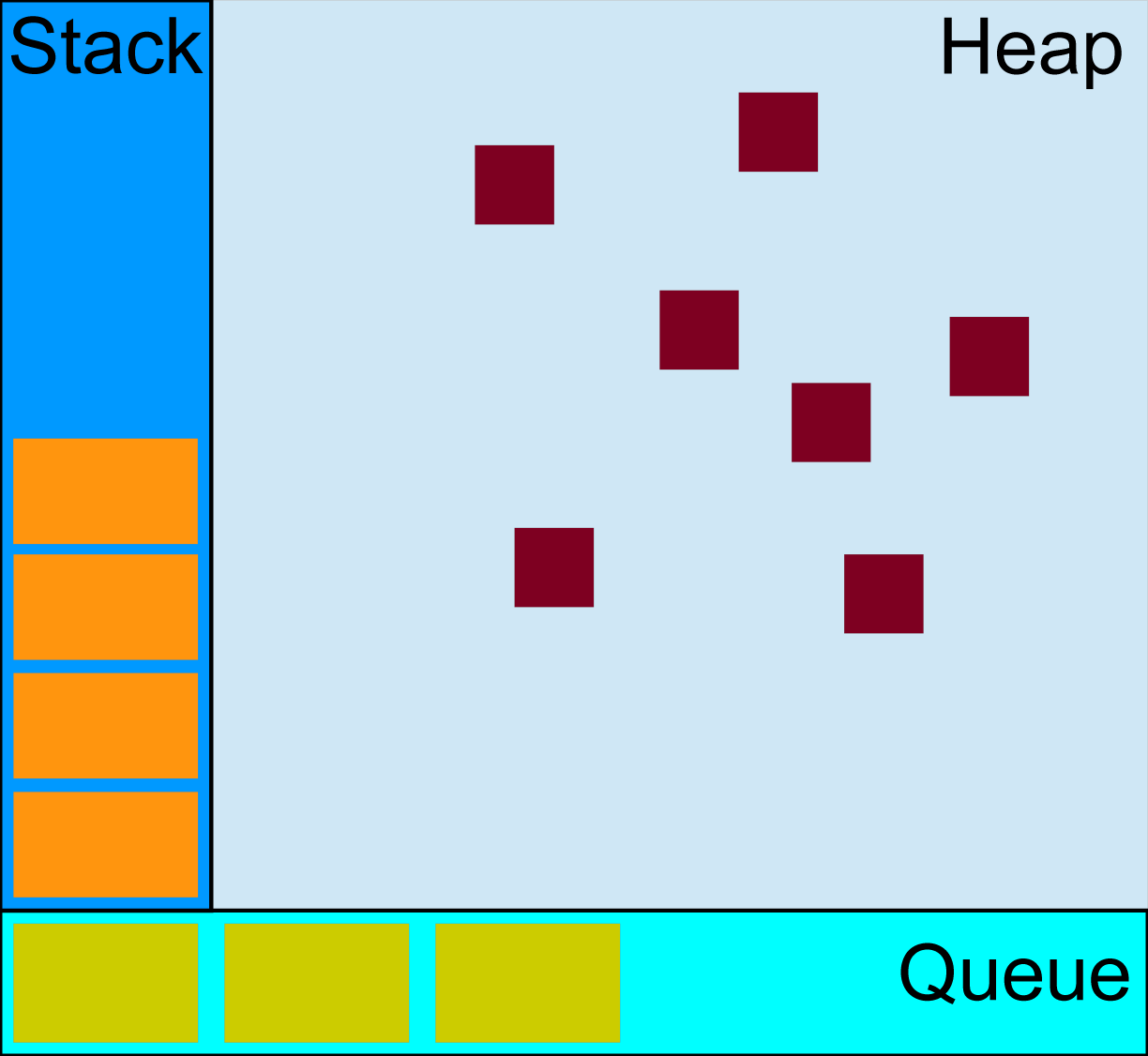
从图中可以看出,组成 JavaScript 内存的主要部分有:调用栈(Call Stack),堆(Heap),回调队列(Call Queue),Web API,以及事件循环。
思考如下代码:
1 | var numberA = 2 |
当执行这段代码时,将会有以下操作:
1、为变量 numberA 创建唯一标识符(identifier)
2、在内存中分配一个地址(在运行时分配)
3、将值 2 存储在分配的地址
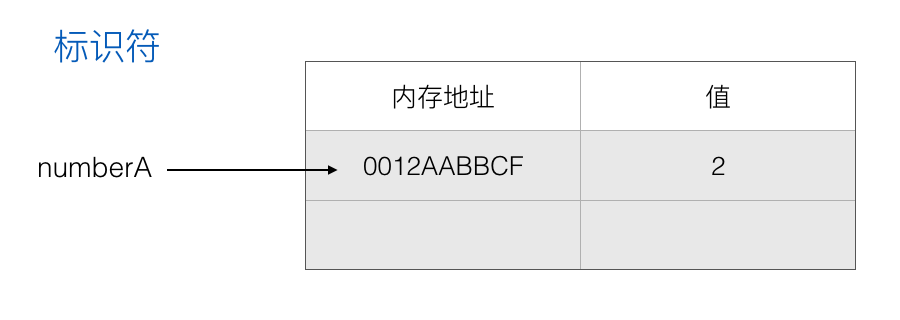
通俗地说是变量 numberA 保存了值 2,其实更准确地说是 numberA 保存的地址的值为 2。
我们再创建一个变量,并把 numberA 赋值给它:
1 | var numberB = numberA |
由于 numberA 指向的是一个内存地址,所以 numberB 也指向了那个内存地址:
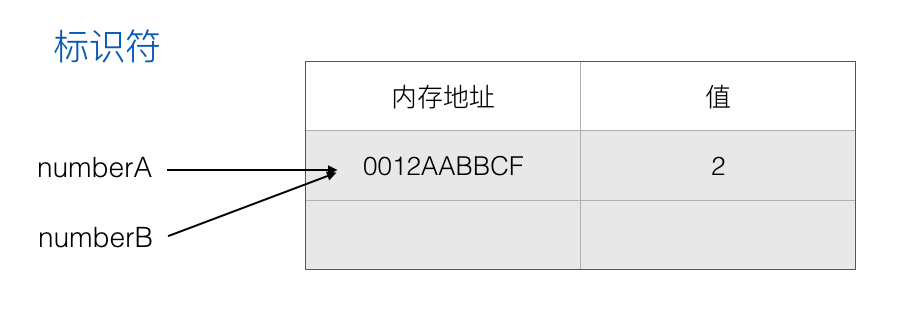
所以访问 numberB 获得的值也是 2。
接下来对 numberA 进行以下操作:
1 | numberA = numberA + 1 |
大家都知道 numberA 的值会变成 3,但是 numberB 并不会随着 numberA 的变化而变化,因为在 JavaScript 中,数字是基本类型值,而基本类型值是不可变的,也就是说该内存为值 2 的内存地址,会一直都是保存值 2:
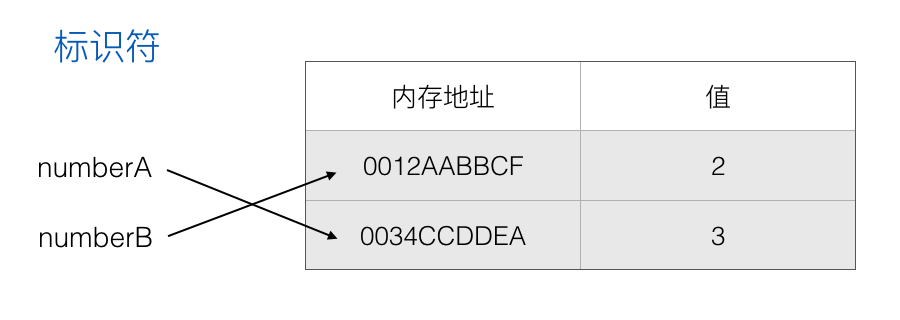
JavaScript 中的变量可能包含两种不同数据类型的值:基本类型指和引用类型值。基本类型值指的是简单的数据段,而引用类型值指那些可能由多个值构成的对象。
简单地说,基本数据类型包括:Undefined、Null、Boolean、Number 和 String(ES6 中新增了 Symbol)。引用类型就是 Object、Array、Function 等。
也就是说处理字符串与以上处理数字是一样的:
1 | var stringA = 'abc' |
对变量 stringA 进行赋值:
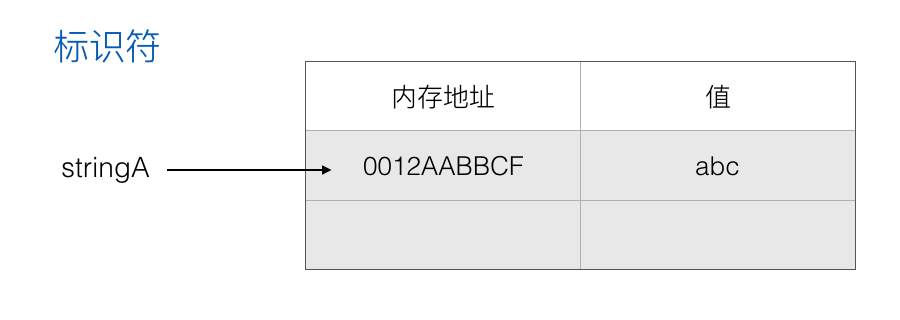
1 | stringA = stringA + 'd' |
对变量 stringA 进行重新赋值:
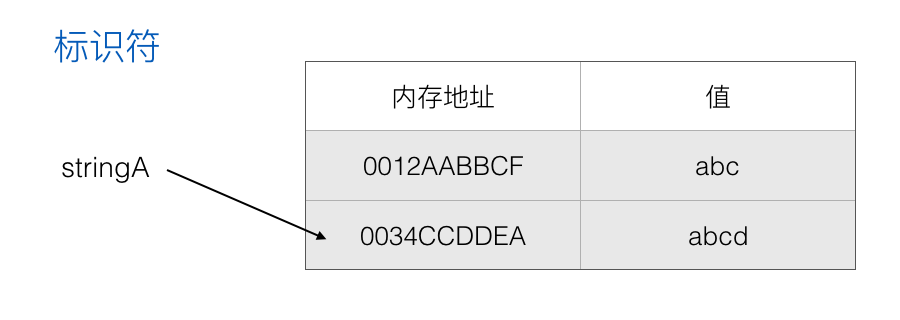
在调用栈中主要保存基本数据类型(也会有函数),堆中主要保存引用类型。

引用类型变量的声明和赋值
思考以下代码:
1 | var objectA = { |
当运行上面的代码时,会发生的情况与上面创建 numberA 的情况类似,但是在 objectA 存储的地址的值将不是对象,而是在堆内存中该对象的地址:
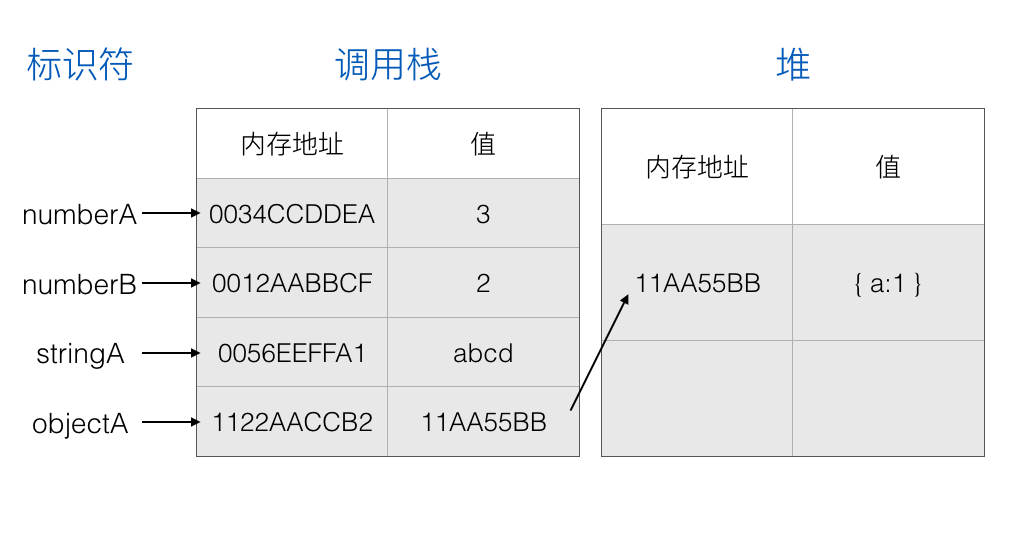
接下来创建一个新变量 objectB 并把 objectA 赋值给 objectB:
1 | var objectB = objectA |
此时 objectB 指向了和 objectA 同样的内存地址:
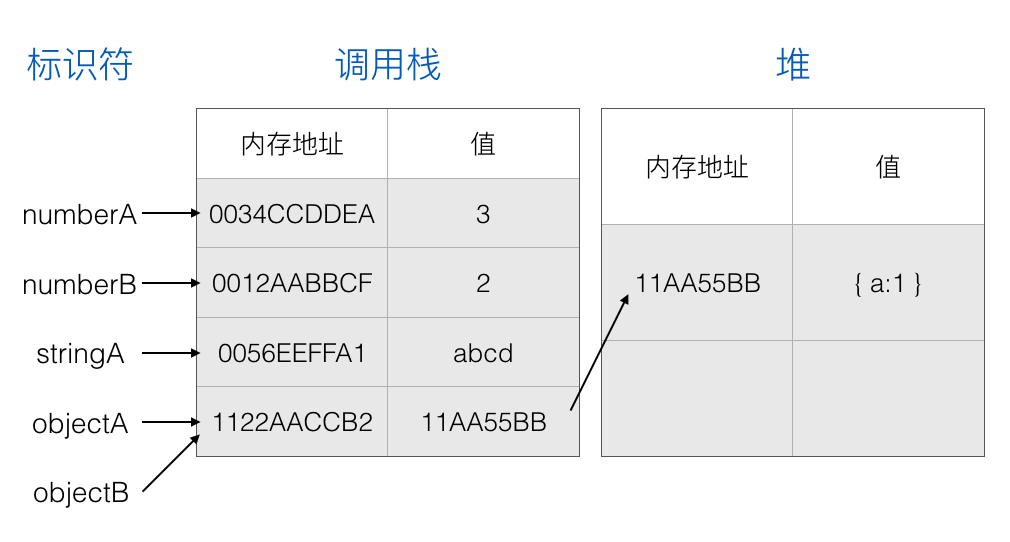
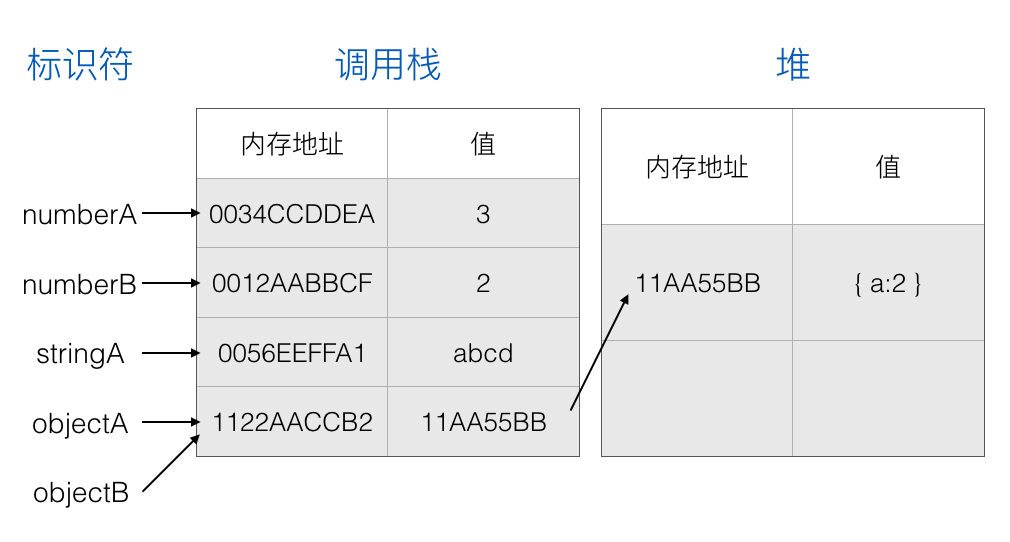
这个时候操作 objectB 所做出的修改也会反应到 objectA 中,因为现在 objectA 和 objectB 指向的是同一个对象:
1 | objectB.a = 2 |
函数的参数传递
在 JavaScript 中所有函数的参数都是按值传递。
思考如下代码:
1 | var numberA = 3 |
在进入 foo 函数时,会把 numberA 和 objectA 的内存地址复制给 foo 函数的局部变量 num 和 obj:
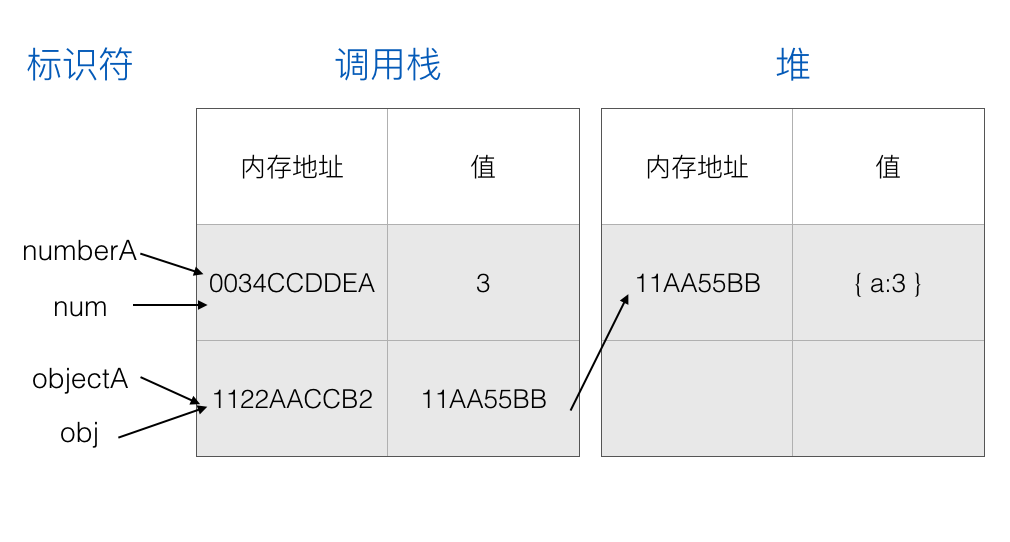
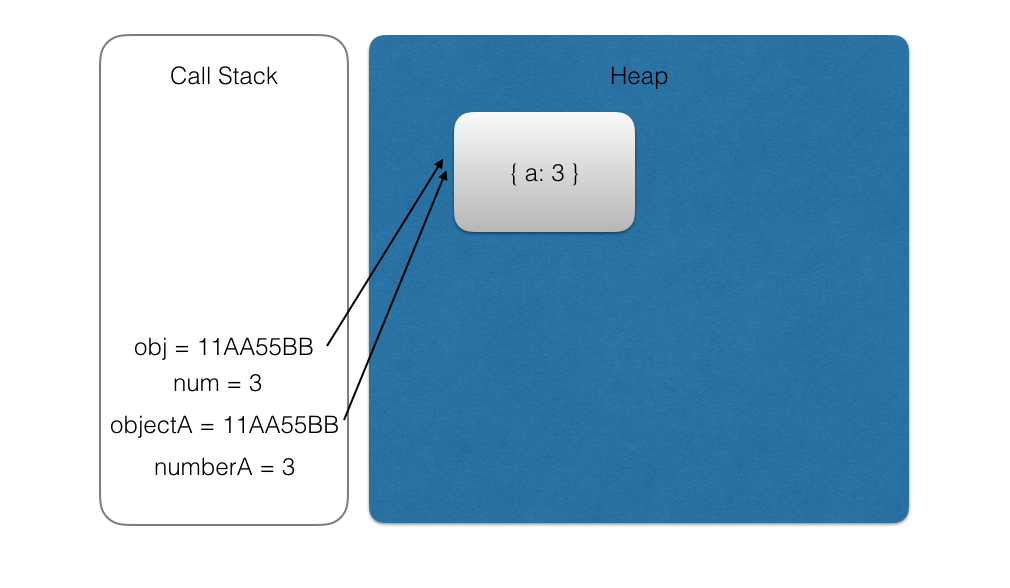
执行 foo 函数的代码,修改相应的变量:
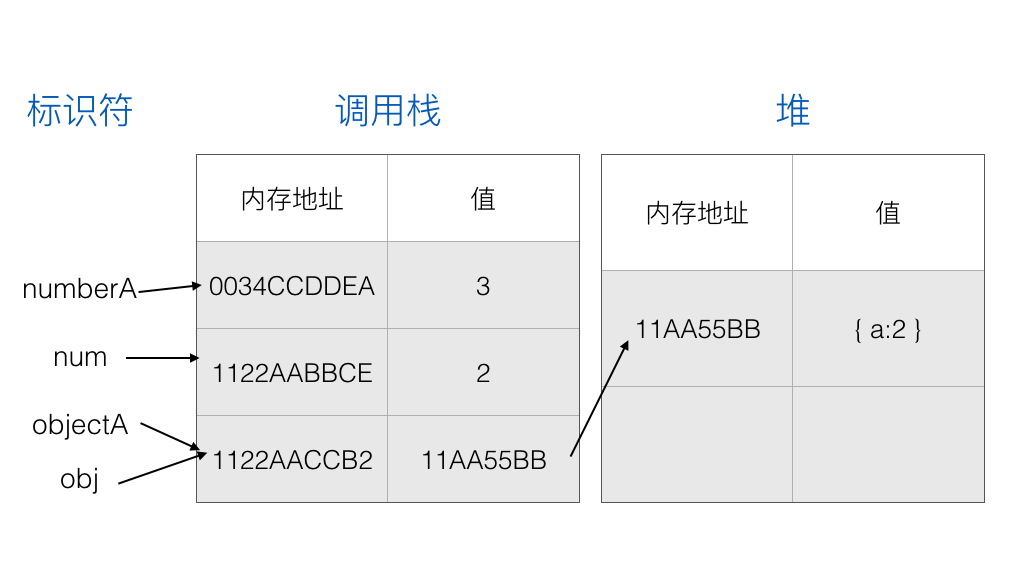
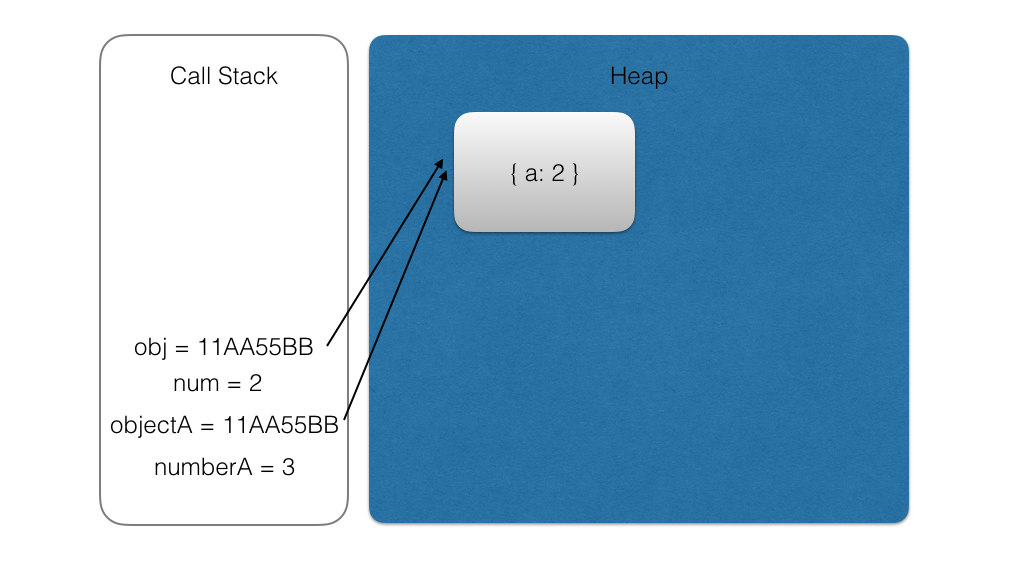
const 声明
用 const 声明的变量是常量,不能被改变其指向。
1 | const arrA = [1] |

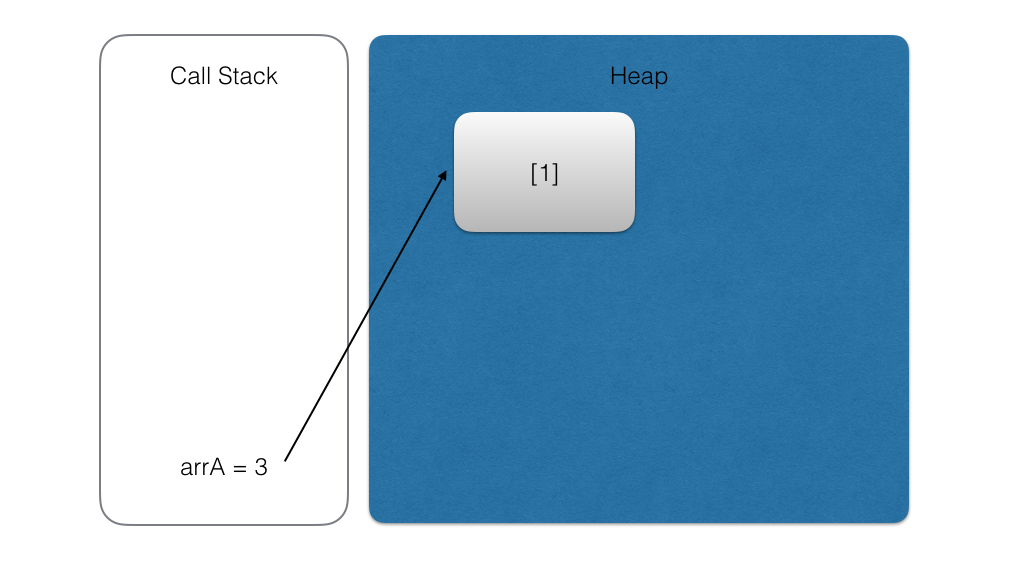
可以对 arrA 指向的数组进行 pop, push, shift 等数组操作:
1 | arrA.push(2) |

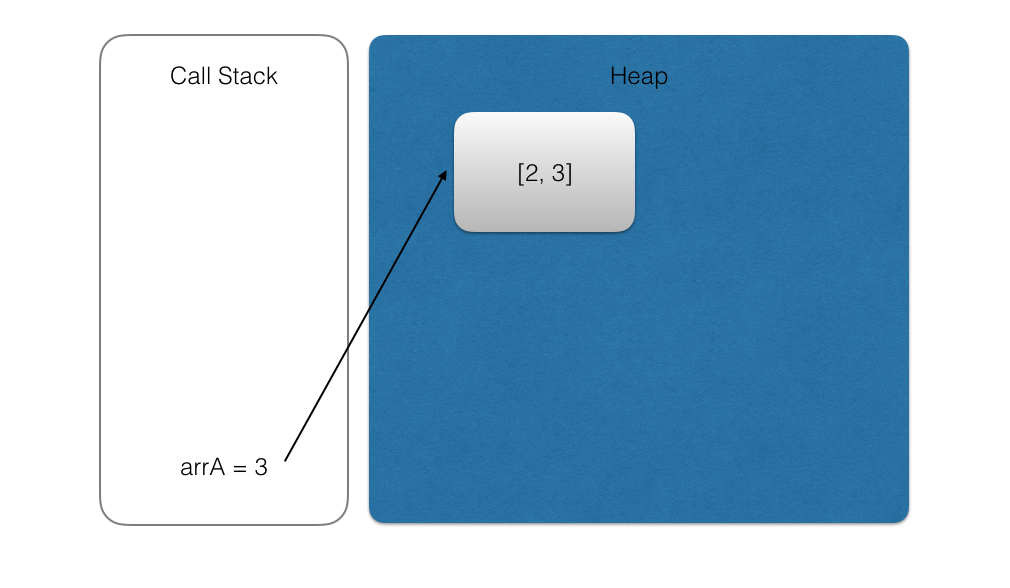
但是不能对其进行重新赋值,也就是不能指向一个新的地址:
1 | arrA = [] // 报错 |
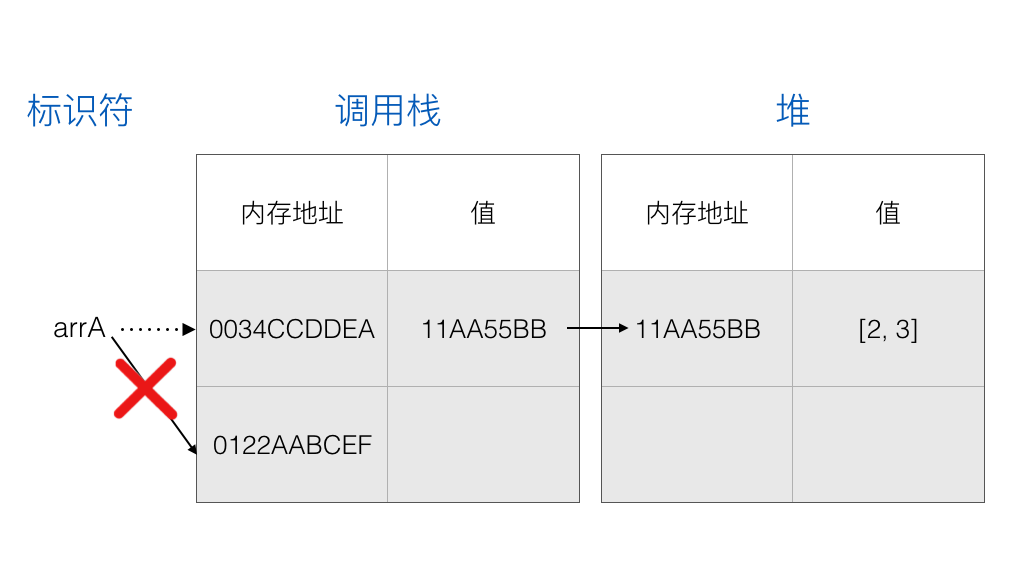
一般来说,我们应该尽可能多地使用 const,只有当我们知道某个变量将发生改变时才使用 let。
总结
- 组成 JavaScript 内存的主要部分有:调用栈(Call Stack),堆(Heap),回调队列(Call Queue),Web API,以及事件循环
- 基本类型的值是不变的,主要存在调用栈中
- 引用类型的值是可变的,主要存在堆中
- 函数的参数传递是值传递,传递的是变量所指向的地址
const声明的变量不能被改变的意思是不能重新指向新的地址- 一般情况我们都尽可能使用
const去声明变量,只有当我们确定知道某个变量会改变时使用let
参考
JavaScript 是如何工作的:JavaScript 的内存模型
《JavaScript 高级程序设计(第三版)》